Group Week Report
模型压缩与部署组工作进度 (2023.4.3-2023.4.9)
高扬城
- I-ViT模块复现:完成I-LayerNorm的复现;
- 基金申请审稿意见回复;
- 长江流域非法活动监测项目初版方案及可行性分析;
- 组会ppt编写;
李亚伟
- workshop
在用L1 charbonnier损失进行预训练后,继续使用L2损失训练 -> PSNR:27.76 -> 27.81 上升
改进注意力模块:1.增大感受野 2.部分卷积用分组卷积替代 -> Params: 25,664 -> 24,160 下降 FLOPs: 2.949 -> 2.776 下降,但是runtime反而上涨了 27.8 -> 30.0,tflite对分组卷积算子的支持不好
目前最好结果
Model Description Dataset Val PSNR Val SSIM Params Runtime on oneplus7T [ms] FLOPs [G] SWAT_5 Sliding Window, VAB Attention, Partial Conv, Channel Shuffle(mix_ratio=1), replace fc with 1*1 conv, replace pixel normalization with layer normalization, enlarge train step numbers to 250,000 REDS 27.811176 0.7763541 25,664 27.6 (FP16_TFLite GPU Delegate) 2.949
- work
- 搜集在REDS数据集上完全相同实验设置的paper,汇总相关指标情况
- 剪枝/权重聚类的代码之前在基于单帧的单输入单输出模型上跑通,现模型多输入多输出,进行调整后现已跑通
后期计划
高扬城
- 完成I-ViT模型复现;
- 完成组会ppt编写;
- 尝试在Jetson nano或raspberry pi上使用TVM进行模型部署;
李亚伟
- work
- 完成当前多输入多输出模型的INT8/FP16的量化部分
模型压缩与部署组工作进度 (2023.7.03-2023.7.16)
李亚伟
- video super-resolution on mobile device
- FANI 代码整理,上传github
- NeurIPS 审稿
- 补充PPT: 模型压缩部署部分
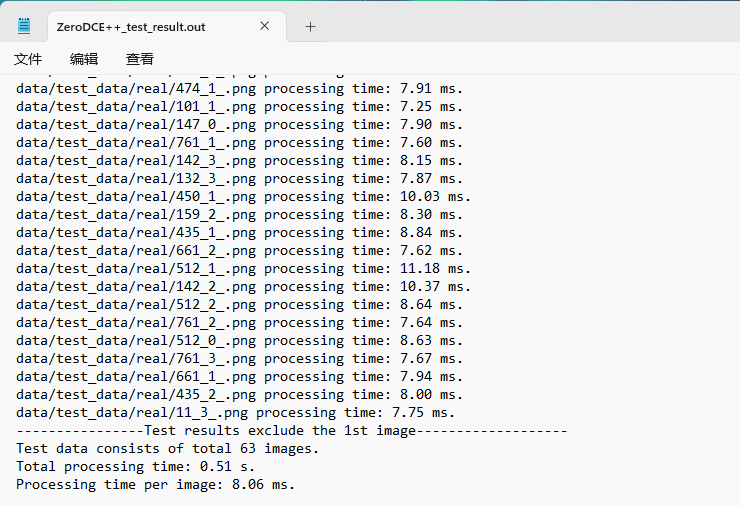
- Jetson Nano 部署 ZeroDCE,远远达不到实时性要求,处理单张512×512图片暗光增强耗时 > 2 min。具体结果如下:
/photo")
苗康
- 调研了李亚伟推荐的几篇量化文献:ZeroQ,HAWQ-V3,调试了 micronet 项目上几个量化操作的 demo:QAT/PTQ -> QAFT
- 请假回家,处理家里一些杂事
后期计划
李亚伟
- 调研了解最新压缩量化进展,寻找下个工作方向
- 8-bit 浮点数量化项目(FP8 quantization)高通已开源,测试了解下有无follow的空间
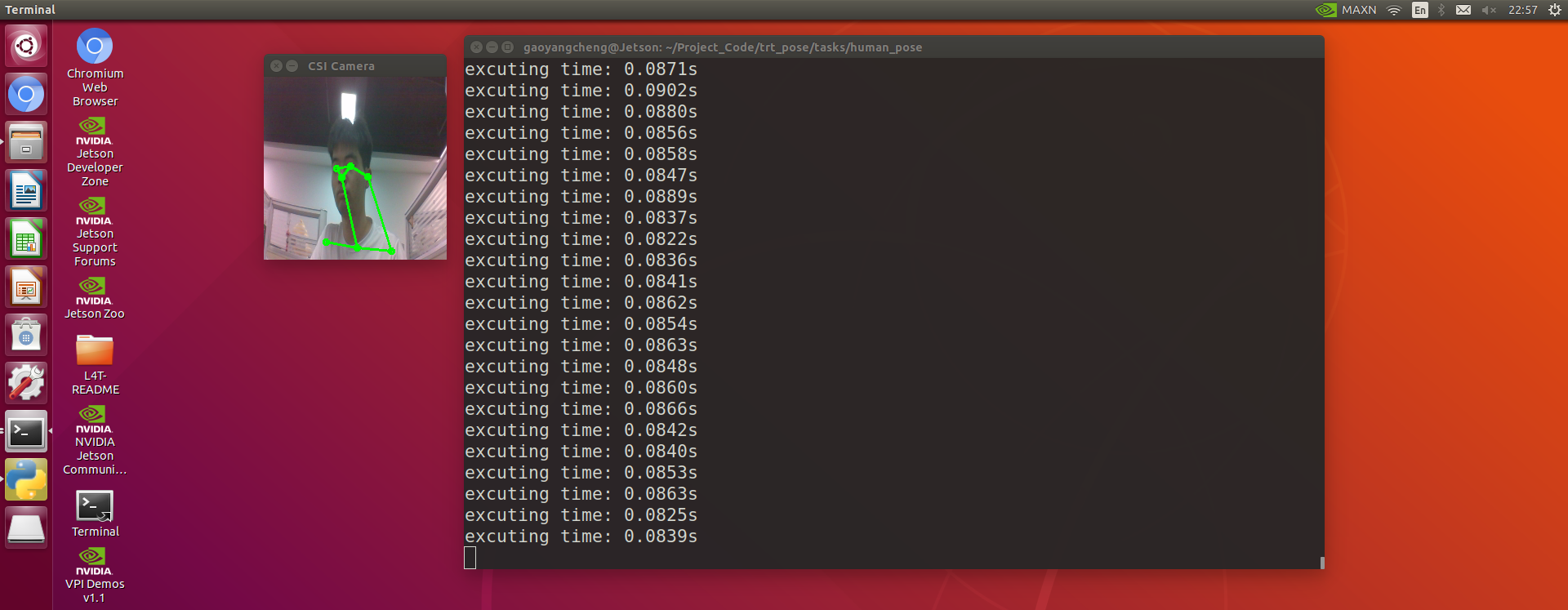
- trt_pose 姿态估计项目摄像头随动功能实现
- Bingda机器人小车文档学习

苗康
- 和模型压缩组内成员讨论下一步的选题方向
- 熟悉模型压缩方向的最新进展
模型压缩与部署组工作进度 (2023.8.07-2023.8.13)
苗康
- 撰写 icdm审稿意见
- 参与韦炎炎师兄项目书撰写,即围绕“复杂环境下对监控画面进行增强和实时分析”主题,调研了两个比较细分的小方向,一篇综述是Areview ofcomputer visionbased structuralhealth monitoring at localand globallevels,利用计算机视觉对建筑进行健康检测;另一篇综述是 Anomaly Detection in RoadTrafic Using Visual Surveillance:ASurvey,调查了基于计算机视觉和视觉监控的技术来理解交通违规或其他类型的道路异常的相关技术
- 撰写开题报告,以轻量化超分为主题
李亚伟
- PRCV审稿
- FP8 Quantization 调研
- FP8 Quantization: The Power of the Exponent (Qualcomm_NeurIPS 2022)
- FP8更适应离群值多的场景
- PTQ时精度优于INT8,QAT时精度比INT8略差
- FP8 FORMATS FOR DEEP LEARNING (NVIDIA/Arm/Intel_ArXiv 2022.09) -> 训练推理统一数据格式FP8
- FP8 可以加速训练和减少训练所需的资源,同时方便部署且可以保证训练出的精度
- INT8 量化模型通常需要进行校准或微调,训练与推理数据类型不一致不便于部署,且通常精度会下降
- FP8 versus INT8 for efficient deep learning inference (Qualcomm_ArXiv 2023.06) -> FP8 目前在性能和精度上不能取代INT8推理,目前INT4-INT8-INT16是边缘端推理的最优解
- PTQ时在离群值显著的情况下,FP8相较INT8有精度优势; 通常这种情况可以通过W8A16混合精度以及QAT来解决
- FP8推理硬件开销大, FP8 MAC 单元效率比 INT8 低50%至180%
- 为了更高效,已经有一些INT4量化的工具, 但到目前为止并没有FP4相关的工作
- Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models (MSRA_ArXiv 2023.05) -> Layer wise混合精度LLM
- FP8 Quantization: The Power of the Exponent (Qualcomm_NeurIPS 2022)
- Jetson Nano 部署暗光增强 ZeroDCE++,处理单张512×512图片耗时约10ms,但有波动(最高4931.46 ms/张),基本满足实时性要求
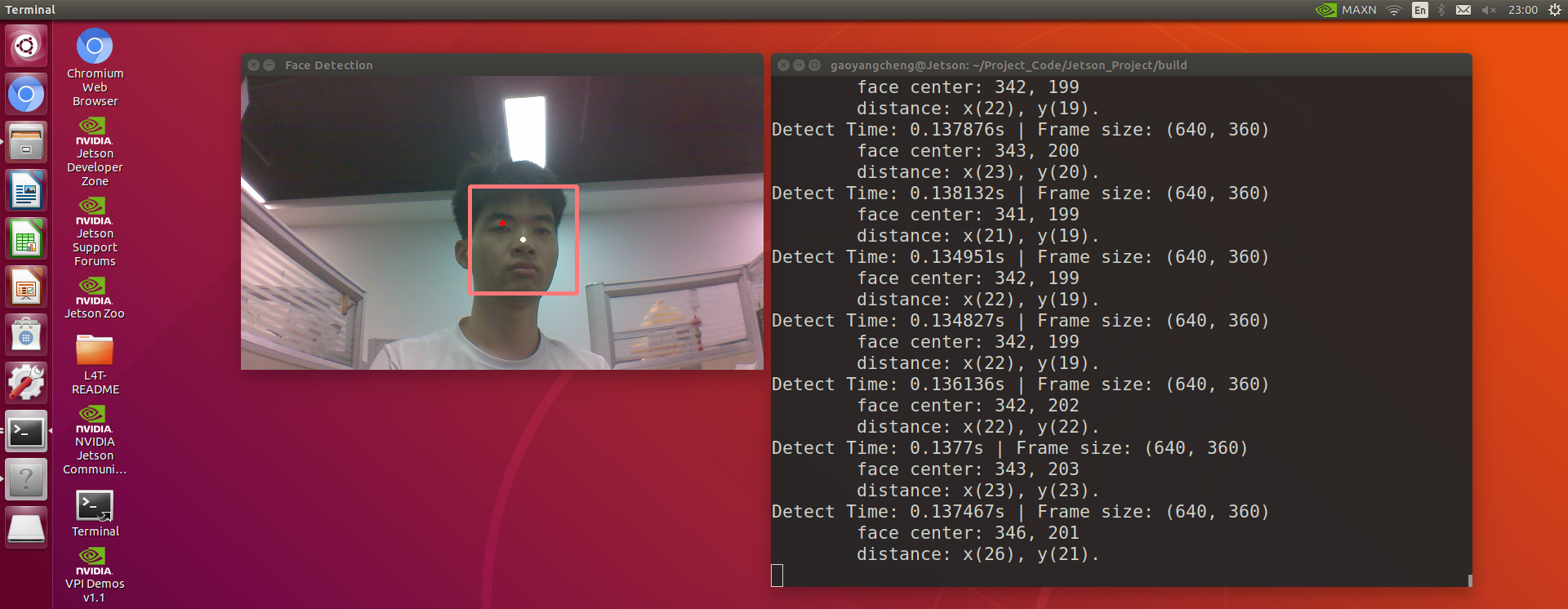
- Jetson Nano 部署 Face Tracking,结合之前的Pose Estimation 达不到实时30 frame/s的要求
后期计划
苗康
- 确定项目书的模板论文,补充项目书
- 寻找新工作的方向
李亚伟
- 撰写开题报告
- 尝试集成Face Tracking 和 Pose Estimation实现相机角度跟随人体并进行姿态估计
模型压缩与部署组工作进度 (2023.8.14-2023.8.27)
苗康
- 完成了项目申请书的撰写工作,在师兄的指导下修改了项目书的背景,相关工作,技术路线等内容
- 开题报告
- 调研并学习了商汤的MOBench 量化工具,针对不同工作的训练pipeline存在差异导致复现结果不同,其提供了统一的理论算法和量化策略。打算作为接下来一段时间的研究方向
李亚伟
- 机载广域持续监视方案调研,PPT制作
- 开题报告
- jetson nano 项目:Face Tracking + Pose Estimation
- 原有基于nvidia官方trt_pose项目的姿态估计推理速度慢,现基于Shanghai AI Lab 2023最新的轻量姿态估计项目RTMPose进行部署
- 调研了解商汤MMdeploy 和 MMPose项目,编译安装相关依赖并在jetson nano上搭建了部署环境
- 完成了驱动舵机调整摄像头位置的C++代码,后续通过ctypes库实现在py文件中调用此部分调整摄像头姿态的C++代码
后期计划
苗康
- 深入了解运用MQBenche
李亚伟
- 完成jetson nano 项目:Face Tracking + Pose Estimation
- 调研了解TensorRT/TNN/MNN/NCNN等推理框架,重点尝试运用TensorRT加速RTMPose的推理
- 参加大湾区算法比赛: 视频插帧 + 单目深度估计
模型压缩与部署组工作进度 (2023.9.25-2023.10.08)
苗康
- 参加视频插帧赛道的比赛,结果不太行。
- 和师兄交流,修改icdm论文里的语法、格式问题。
- 找到一篇23CVPR的论文“CABM: Content-Aware Bit Mapping for Single Image Super-Resolution Network with Large Input”,其动机与我icdm大致相同,区别在于这篇论文为每个patch选择量化比特,我的论文为每个patch选择block数。而且这篇论文很大程度上借鉴了21CVPR “ARM: Any-Time Super-Resolution Method”依然能中,说明这个方向仍然可以继续探索。
王明申
审硕士论文抽检
和师兄一起参加大湾区比赛,熟悉比赛流程,学习不同任务的模型调参工作等。
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models(arXiv 23.10.05)PTQ的时间 QAT的精度
- 动机:现有PTQ量化在DM中W4A4量化时无法产生较好效果,QLoRA缺点:无法将LoRA权重与量化模型权重相融合。
- 提出量化感知低秩适配器QALoRA,将LoRA权重与FP模型权重合并共同量化至目标位宽,权重量化:channel-wise,激活量化:layer-wise。
- Activation量化:将LSQ量化方法运用在每一步去噪步骤中,单独优化激活量化尺度。
李亚伟
- 大湾区单目深度估计比赛:
- 数据的理解存在偏差,涉及共计6个不同数据集的ground truth, label的标签意义未能理解清(如单位mm还是m, skymask, validmask等等)
- 选择部分结构清晰(仅包含imgs, gts)的数据集送入目前的SOTA模型 ZoeDepth 对其 metric bins module 进行微调,结果训练后的精度比原作只在 NYU Depth V2 数据集上进行微调的效果还差
- 目前的提交的结果:A榜 42/60, B榜决定最终排名尚未出结果
- ICDM camera ready 版本修改/国奖申请答辩
后期计划
苗康
- 研究CABM的量化部分,然后迁移到我借鉴的baseline论文“Adaptive patch
exiting for scalable single image super-resolution”里看看效果。
王明申
- 从ECCV 2022 CADyQ和CVPR2023 CABM 两篇论文中,寻找优化量化SISR任务的角度。
- 从其他方向寻找量化工作角度,如大模型Diffusion Model。
李亚伟
- 参照SISR量化思路(ECCV 2022 CADyQ, WACV 2022 DAQ),搭建基于目前SOTA模型 (BasicVSR++/VRT/RVRT) 的量化baseline
模型压缩与部署组工作进度 (2023.10.09-2023.10.15)
苗康
- 注册提交icdm终稿
- 研究几篇超分量化相关工作ARM、CABM、CADYQ代码,ARM代码有一处存在疑问,作者暂未回复
- 确定工作思路,即基于patch确定对应的网络block数,再根据block数确定量化位数,不过原理方面解释性不强
王明申
- 复现SR量化任务APE、CADyQ、CABM模型中baseline效果
- 寻找SR量化trick
- EQ-Net:Elastic Quantization Neural Networks(ICCV 2023)
OFA 动机:不同硬件支持的量化形式多样,现有解决方案局限性需要迭代训练优化- 对于权重量化提出从偏度和峰度信息正则化
- 提出GPG类似知识蒸馏结构组渐进式指导,CQAP MLP结构选择粒度和对称性,最后用遗传算法加快搜索
李亚伟
- Video Super-Resolution Quantization
- 基于目前在Vid4、Vimeo90k、REDS数据集上SOTA模型 BasicVSR++ 进行channel-wise distribution-aware 量化pipeline的搭建(目前尚没有视频超分量化超分方向的baseline,代码难度较大)
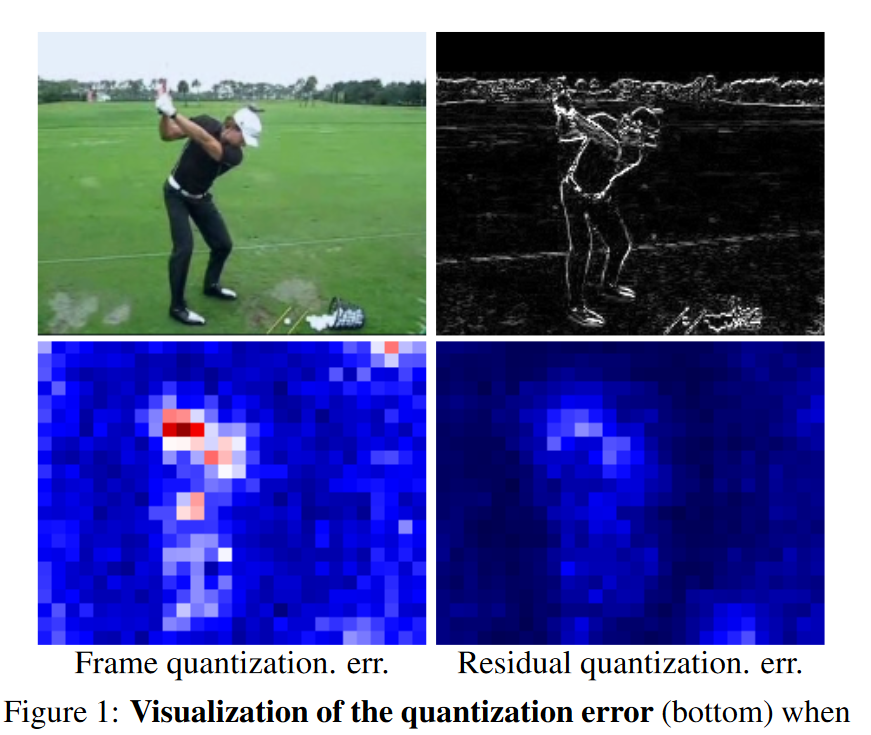
- 尝试引入在其它视频感知任务(Human Pose Estimation,Semantic Segmentation,Video Object Segmentation)有效上的方法,参考 ICCV2023 ResQ 将网络中相邻帧的激活之间的残差用于量化,更小的方差有利于缩小量化误差
- ICDM注册提交
后期计划
苗康
- 根据上述工作思路,继续搭建模型架构,同时查找相关论文,思索更好的原理解释
王明申
- 继续寻找SR量化trick
- 深度阅读现有SR量化工作代码
李亚伟
- 结合 ResQ 完成 BasicVSR++ 量化pipeline的搭建
模型压缩与部署组工作进度 (2023.10.16-2023.10.22)
苗康
- 继续上周计划,基于patch做超分量化任务,调试代码,修改模型结构
- 修改专利
- 调研了几篇剪枝超分方面的文章,Aligned Structured Sparsity Learning for Efficient Image Super-Resolution (nips2021), Learning efficient image super-resolution networks through structural regular pruning (ICLR2022), 结论是由于超分网络存在不少跳连和残差,剪枝在超分领域应用的泛化性不是很好
王明申
- SCIS审稿
- 通过pdb方式阅读SR量化代码
李亚伟
- Video Super-Resolution Quantization
- 参考 GPTQ 完成了 BasicVSR++ (未涉及ViT)量化的基础部分
- 阅读论文,了解其它几个SOTA模型(ViTs)是否有需要单独改进的模块:
- CVPR2022: TTVSR
- NIPS2022: PSRT, RVRT
- CVPR2023: IART
- SelecQ latex 排版调整,期刊注册提交
- 学校HPC实例到期, 实验室浪潮集群上 Docker 镜像搭建
- 专利修改
后期计划
苗康
- 继续搭建模型结构
王明申
- 阅读ICCV2023中Workshop关于Low-Bit Quantized Neural Networks的汇报
- 阅读Transformer或LLM有关量化的文章
李亚伟
- 结合 ResQ 改进视频超分ViTs量化模块
- 深度神经网络课程PPT制作
模型压缩与部署组工作进度 (2023.10.23-2023.10.29)
苗康
- 初步搭建出基于patch的超分量化框架,效果很差,判定是代码问题,又因为存在创新型的问题,暂时放一放
- 与组内协作,参与视频超分工作,研究BasicVsr++视频超分模型。
王明申
阅读论文
- VSR:BasicVSR(CVPR 2021)、BasicVSR++(CVPR2022)
- Quantization:
- EfficientViT(ICCV 2023 MIT Transformer轻量化 对分类、分割、复原三个领域中general的模型轻量化且效果极好)
- Solving Oscillation Problem in Post-Training Quantization Through a Theoretical Perspective(CVPR 2023 从量化误差导致震荡角度出发,优化量化结果)
跑通BasicVSR++代码
通过TensorRT量化框架对Yolov7模型实现自动插入量化节点量化,mAP掉了0.03%
李亚伟
- Video Super-Resolution Quantization
- 试用百度 paddleslim 分别用静态动态量化(PTQ)对 BasicVSR++ 进行量化
- 深度神经网络课程PPT制作
后期计划
苗康
- 参与视频超分工作
王明申
- 阅读量化文章
- 学习网络模型量化,并完成VSR任务量化
李亚伟
- 配合完成 paddleslim 量化 BasicVSR++
模型压缩与部署组工作进度 (2023.10.30-2023.11.05)
李亚伟
- Video Super-Resolution Quantization
- BasicVSR++ PTQ: 量化过程有bug正在解决
- BasicVSR++ torch模型转onnx模型并检查
- 激活校准,产出量化参数: scale zero_point
- 权重调整,提升量化精度
- 量化误差分析,定位量化问题
- note: 目前 BasicVSR++ 的 PTQ 基于开源工具 Dipoorlet 进行,优点代码简洁明了易修改,相较百度框架 paddleslim 便于快捷验证idea; VSR 量化方法成熟后可进一步迁移至 paddleslim
- BasicVSR++ PTQ: 量化过程有bug正在解决
- 读文献找idea提升PTQ精度
苗康
一篇 Neural Network 审稿工作
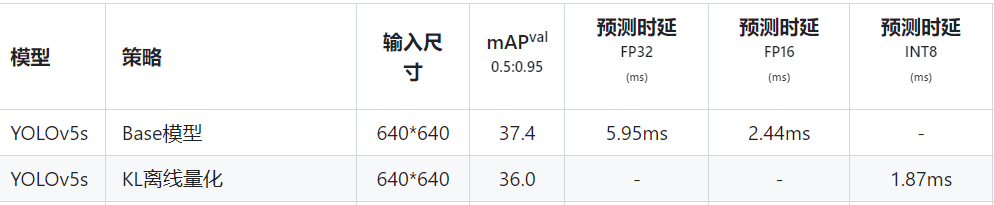
参考 paddleslim 官方文档示例完成yolov5 PTQ:
- 将pytorch的pt文件转化为onnx格式
- 将onnx文件输入paddleslim执行脚本输出模型及权重文件
- 迁移部署到tensorRT平台部分暂不清楚
- 结果:
王明申
- 阅读论文
- VSR:ESPCN(CVPR 2017)
- Quantization:
1. Efficient LLM Inference on CPUs (arxiv 2311.00502, Intel 精度几乎无损)
2. DAQ: Channel-Wise Distribution-Aware Quantization for Deep Image Super-Resolution Networks (WACV 2022 ISRQ; 在Ablation Study中分析了 Gaussian, Uniform, Laplacian, Gamma分布对channel-wise量化的影响)
- ICASSP 2024审稿
- 完成对YOLOv7网络模型的手动量化节点插入,并通过敏感层分析,逐层网络分析及打印量化对精度影响最大的Top10层。
后期计划
苗康
- paddleslim yolov5 PTQ 过程迁移到 BasicVSR++ 上
- 尝试将 ResQ 思路用 paddleslim 实现
王明申
- 阅读量化文章,寻找新的视频超分量化idea
- 学习网络模型量化
李亚伟
- 解决 dipoorlet 量化 BasicVSR++ 遇到的bug
模型压缩与部署组工作进度 (2023.11.06-2023.11.12)
苗康
- 深度神经网络原理课程ppt制作。
- 利用paddleslim其中的AutoCompression接口对yolov5进行自动压缩(包括量化和蒸馏两部分),代码中numpy库的api有冲突,在调试。
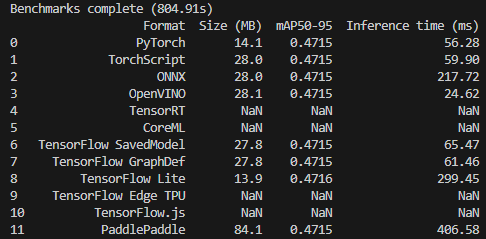
- 利用3090比较了各类框架在yolov5上的部署测试。
王明申
- 阅读论文
- VSR:DRDVSR(CVPR 2018)
- Quantization:Overcoming Distribution Mismatch in Quantizing Image Super-Resolution Networks(解决正则化损失与复原损失冲突问题)
- Neurocomputing审稿
- 完成YOLOv7网络PTQ、QAT量化学习,从手动加入QDQ节点,到逐层分析量化的敏感度,对于敏感度高的层进行处理,对输入Concat节点前的多个输出节点做统一scale处理,最后通过训练迭代优化量化损失,导出量化模型的ONNX模型。
- 分析VSR量化任务的难点,早期VSR任务模型具有更简单的网路结构,近几年的VSR任务模型结构中可能含有不利于通用量化的网络模块,这样就需要手动去加入适配的QDQ节点,难度大且无法做公平的对比实验。
李亚伟
Video Super-Resolution Quantization
- BasicVSR++ 采用
DipoorletPTQ: 量化过程有不支持动态输入的问题, 即不支持视频随机长度(time_step)的问题, github提了issue 暂未有回复 - BasicVSR++ 采用
MQBenchPTQ: BasicVSR++ 模型 forward 过程存在动态控制流, 即控制流的判断条件含有运算变量(Input/Activation)参与, 而MQBench调用torch.fx的symbolic_trace完成 forward 过程计算图捕捉, 其本身的限制不支持动态控制流。正尝试:- 把模型的动态控制流用静态的代替
- torch 2.0 新发布的
torch.compile也即 (TorchDynamo), 了解后尝试来解决模型 forward 中广泛存在的动态控制流
- BasicVSR++ 采用
RustDesk 中继服务搭建, 降低远程桌面的延迟
后期计划
苗康
- 解决自动压缩的bug, 采用paddleslim对yolov5 PTQ, 分析其量化分析工具及精度重构工具。
王明申
- 从较早的VSR任务模型开始着手, 类比用TensorRT框架对YOLOv7的量化尝试对VSR模型进行量化。
- 学习对于不同结构的量化op方法。
李亚伟
- 推进 VSR 模型的常规量化(Naive PTQ)的工作
- 实习相关工作















